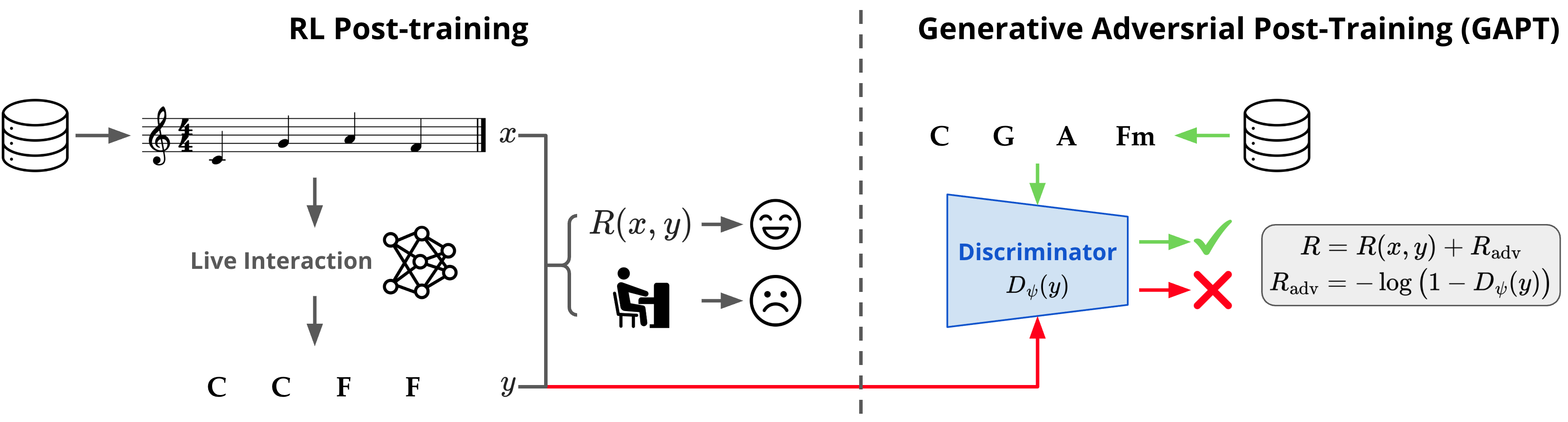
Generative Adversarial Post-Training (GAPT)

I am a PhD candidate in Computer Science at the University of Montreal and Mila.
I am fortunate to be co-advised by
Professor Aaron Courville
and Professor Chengzhi Anna Huang.
My doctoral research focuses on audio understanding, music generation, creative and compositional
generative models, and real-time interactive models in music.
I am a percussionist who has performed timpani in orchestral settings. In my spare time, I also enjoy
playing the guitar and harmonica.
I will be looking for a industry position in late 2025.
Generative Adversarial Post-Training (GAPT)
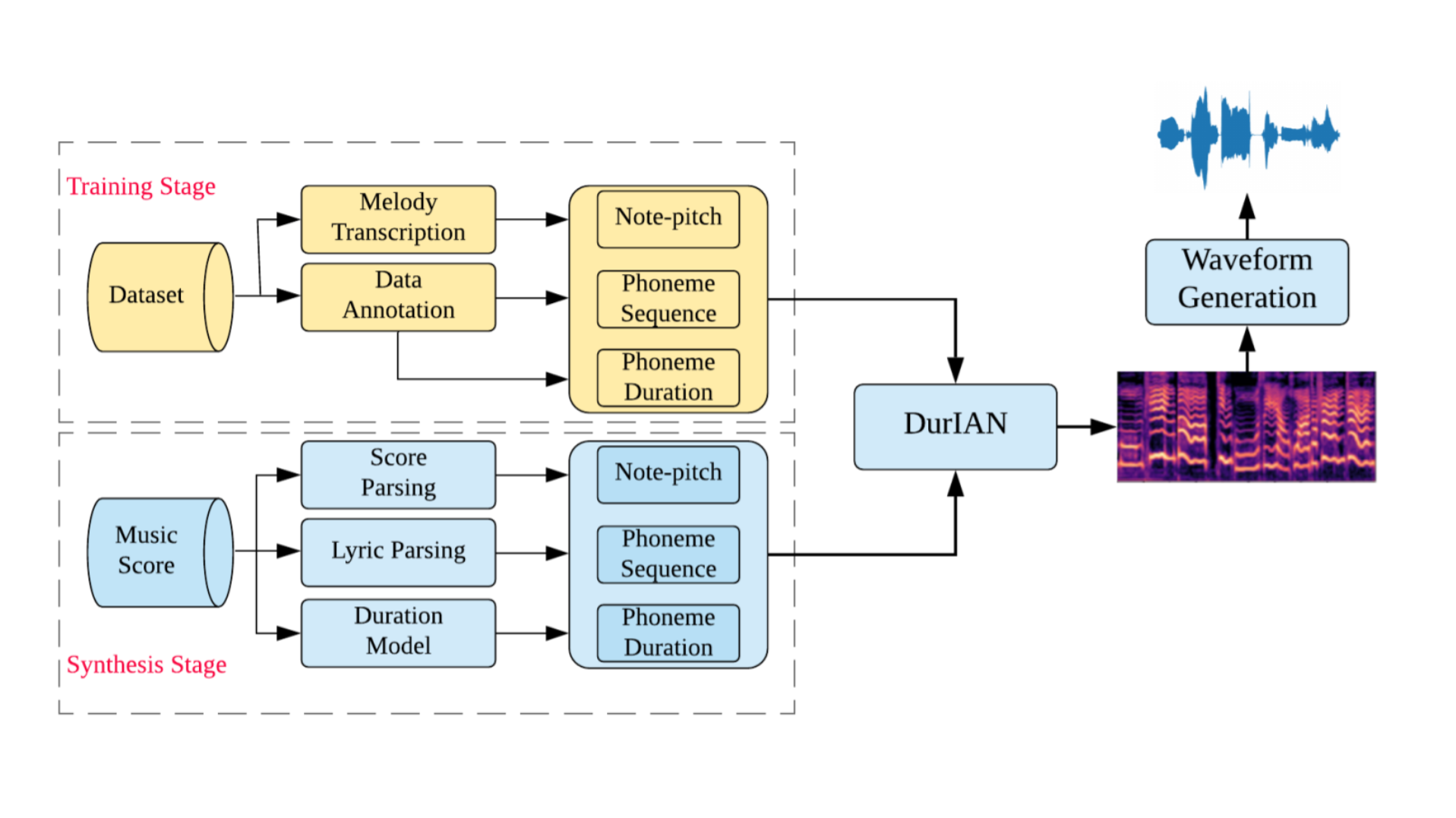
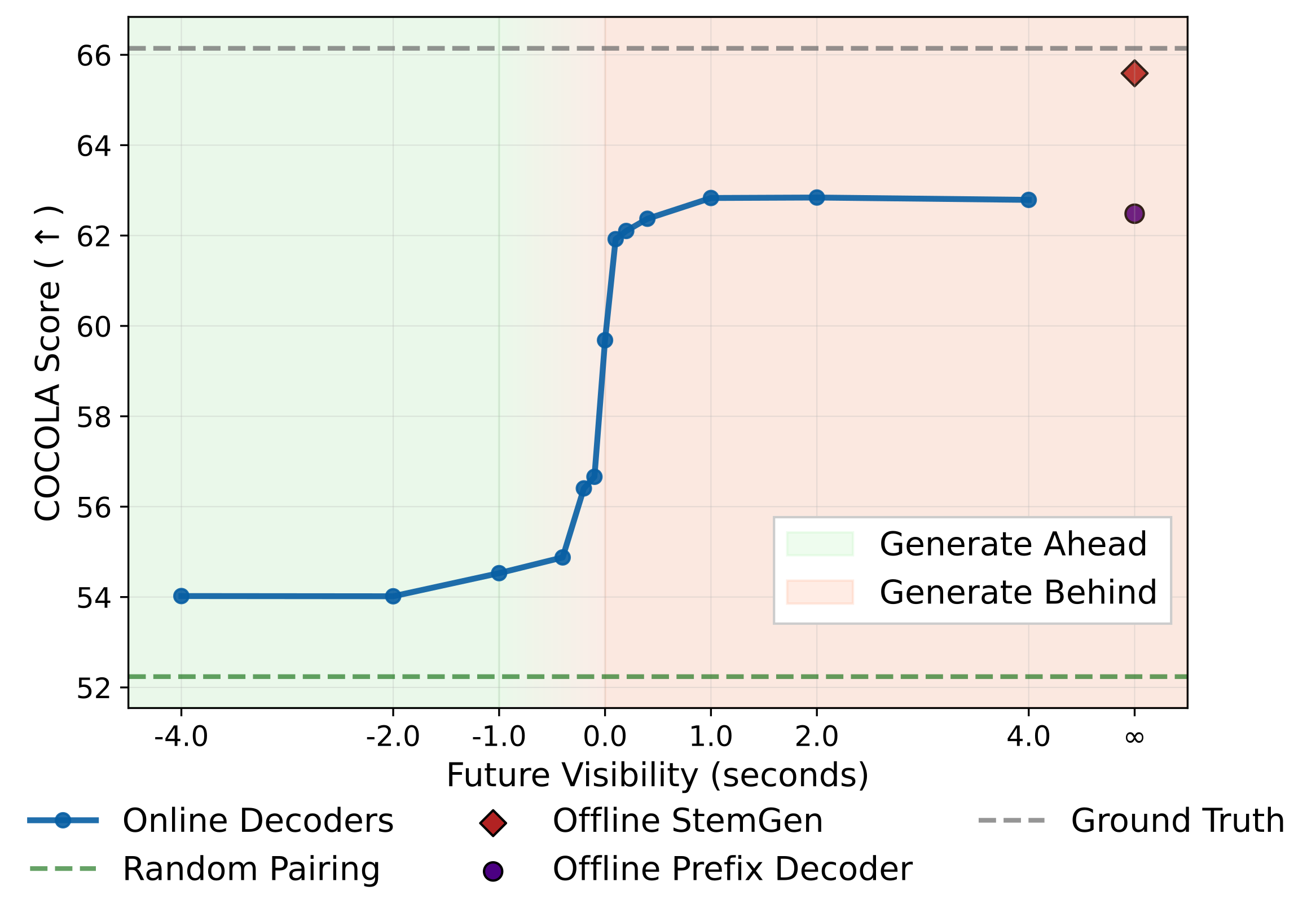
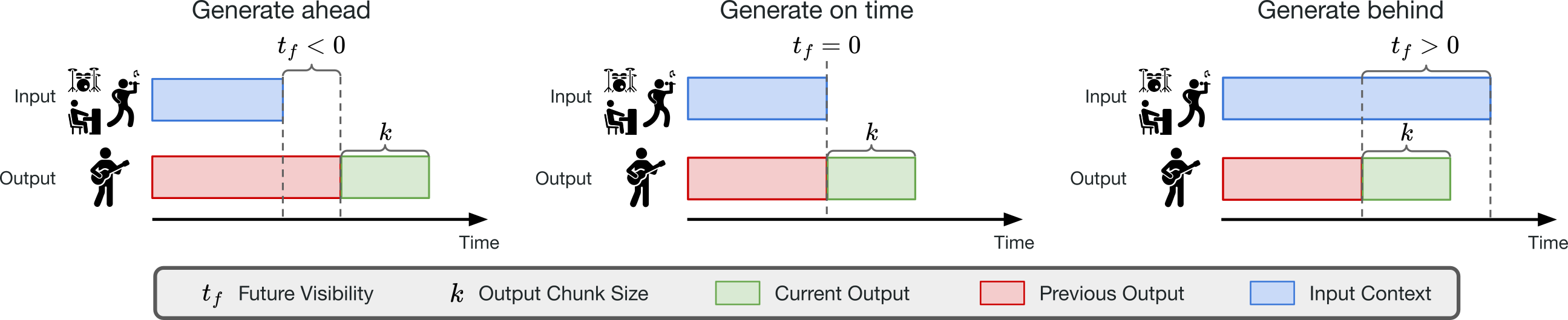
Streaming Generation for Music Accompaniment
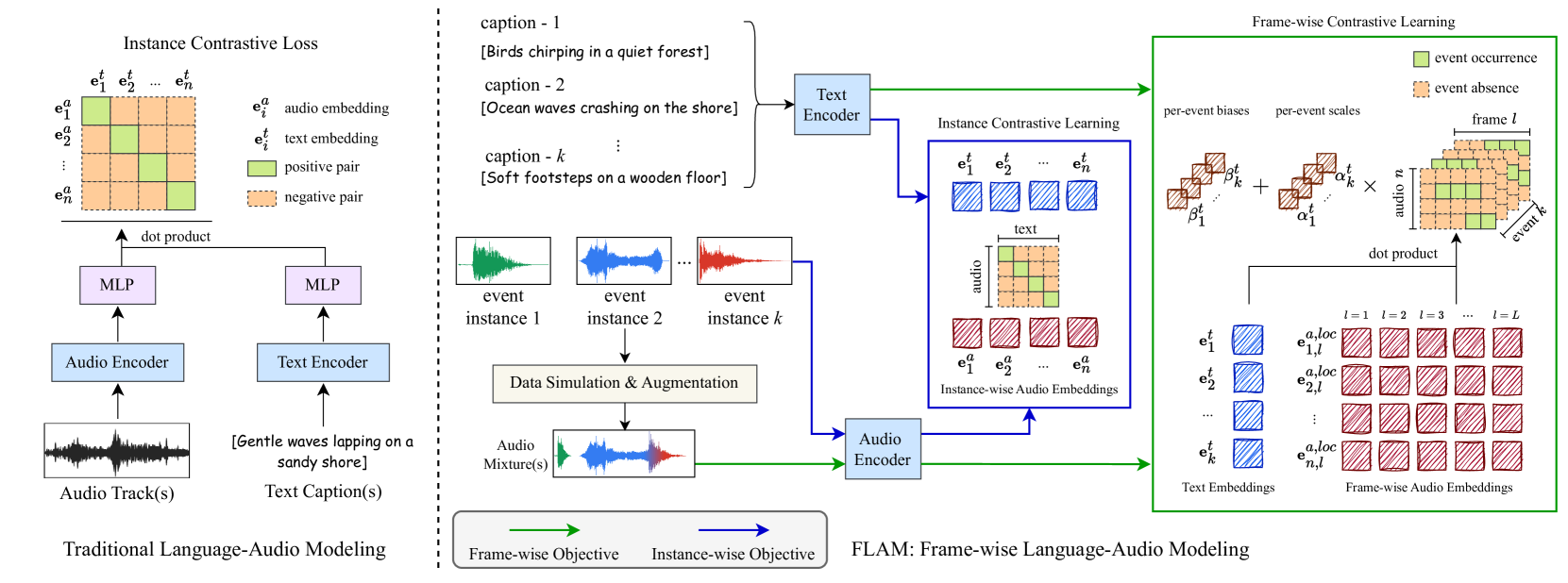
FLAM: Frame-wise Language-Audio Modeling
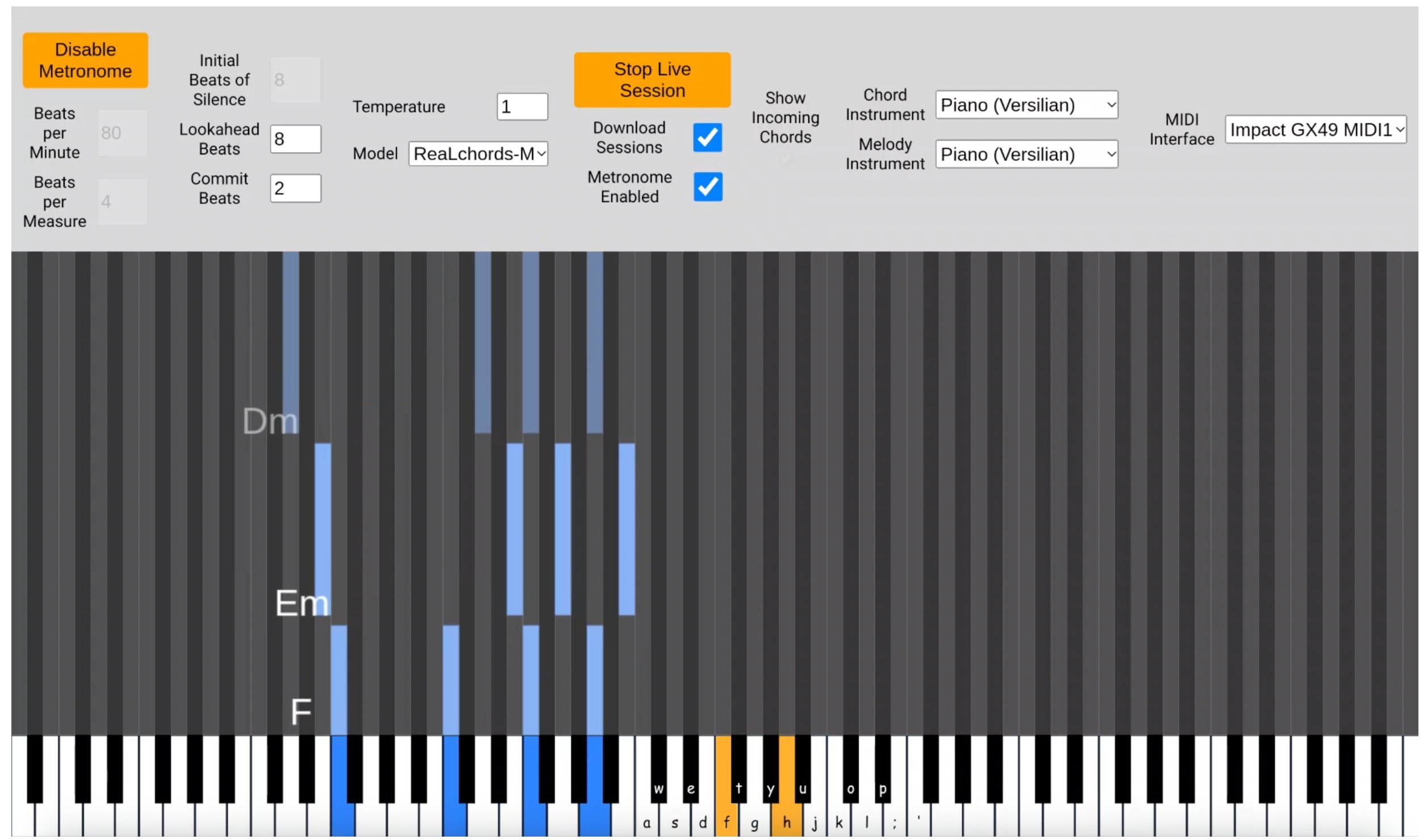
ReaLchords and GenJam: Real-time Melody-to-chord Accompaniment via RL
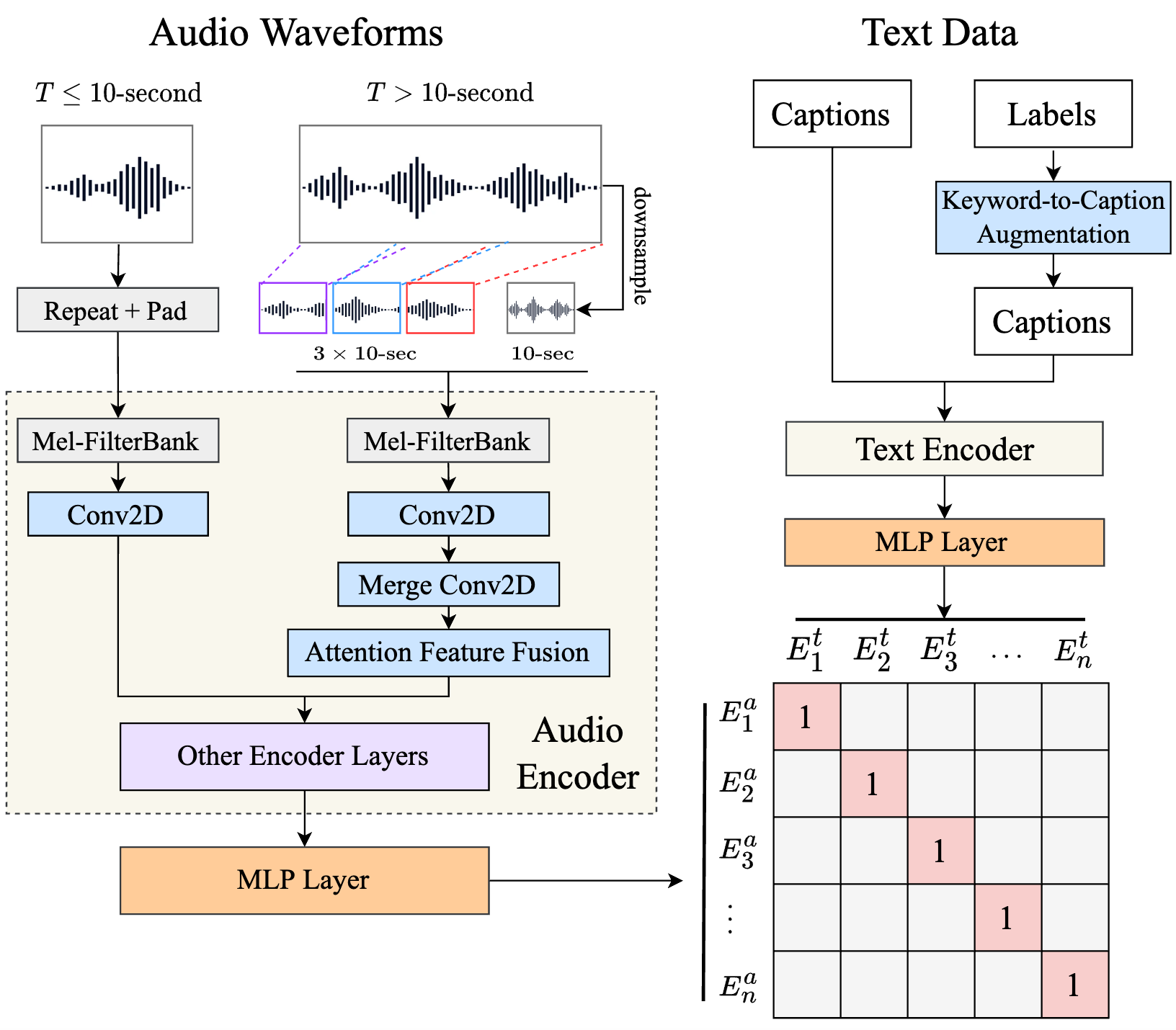
CLAP: Large-scale Contrastive Language-audio Model
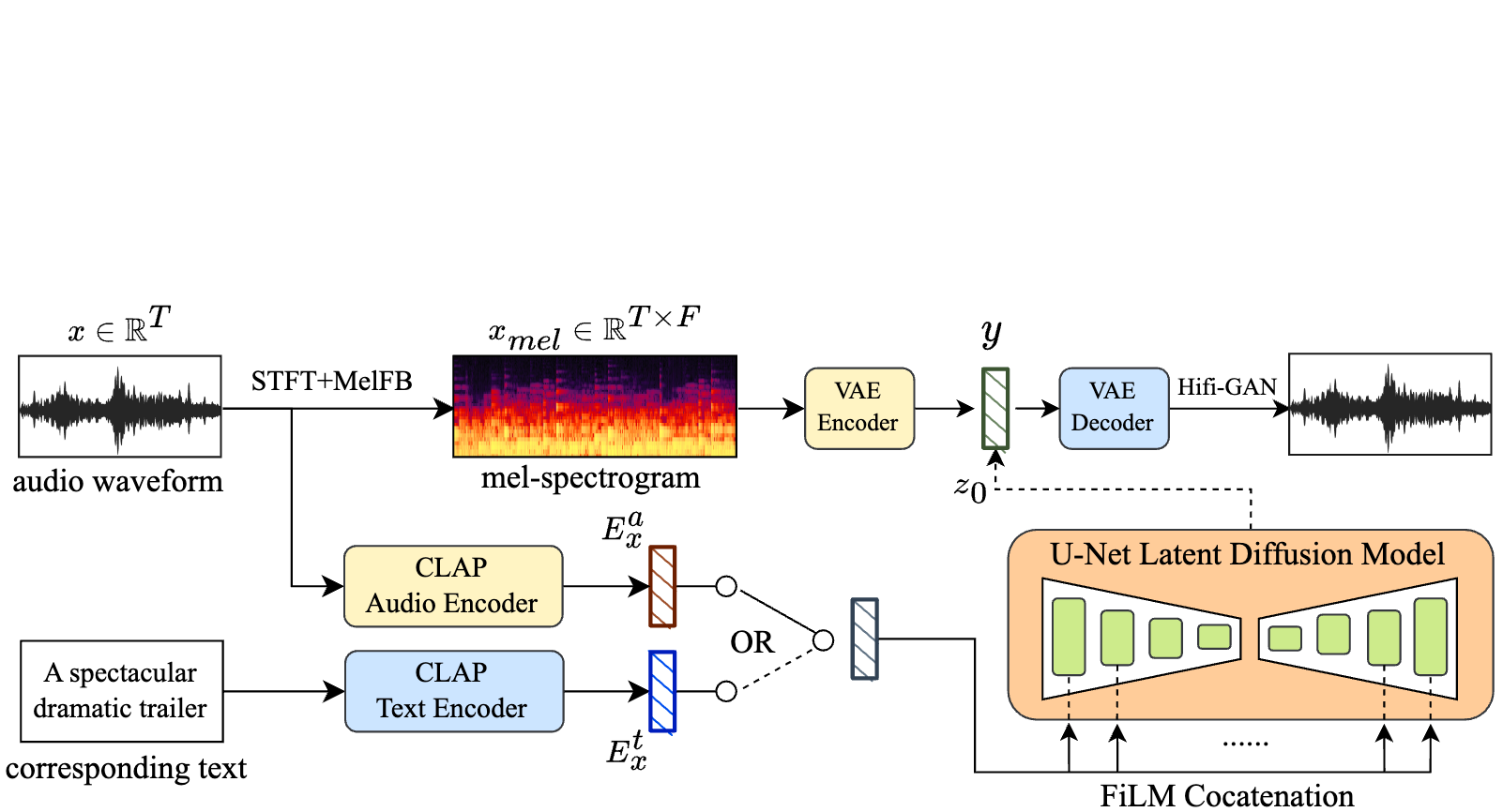
MusicLDM: Text-to-Music Generation with Mixup
3rd Place at AI Song Contest 2022

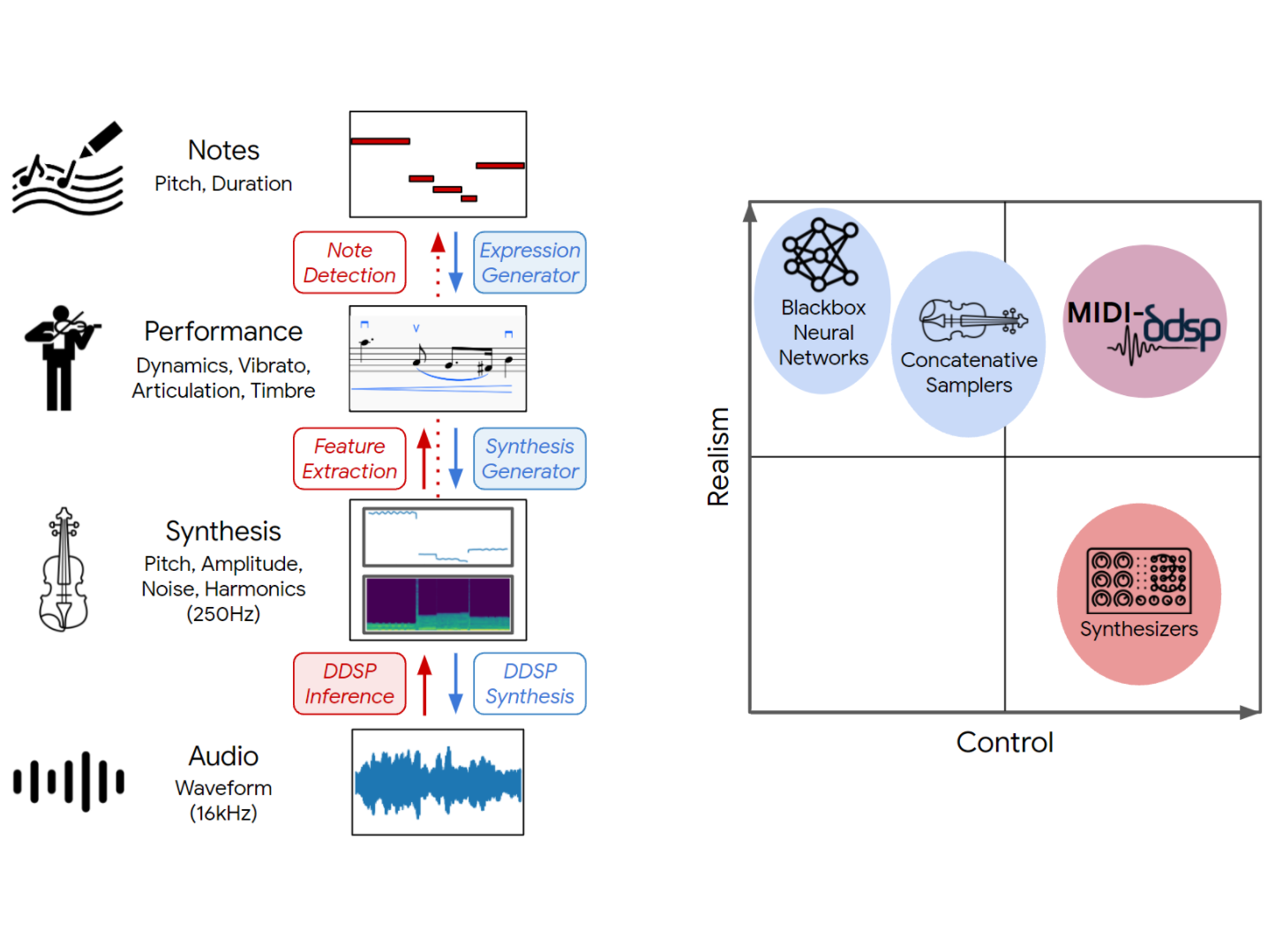
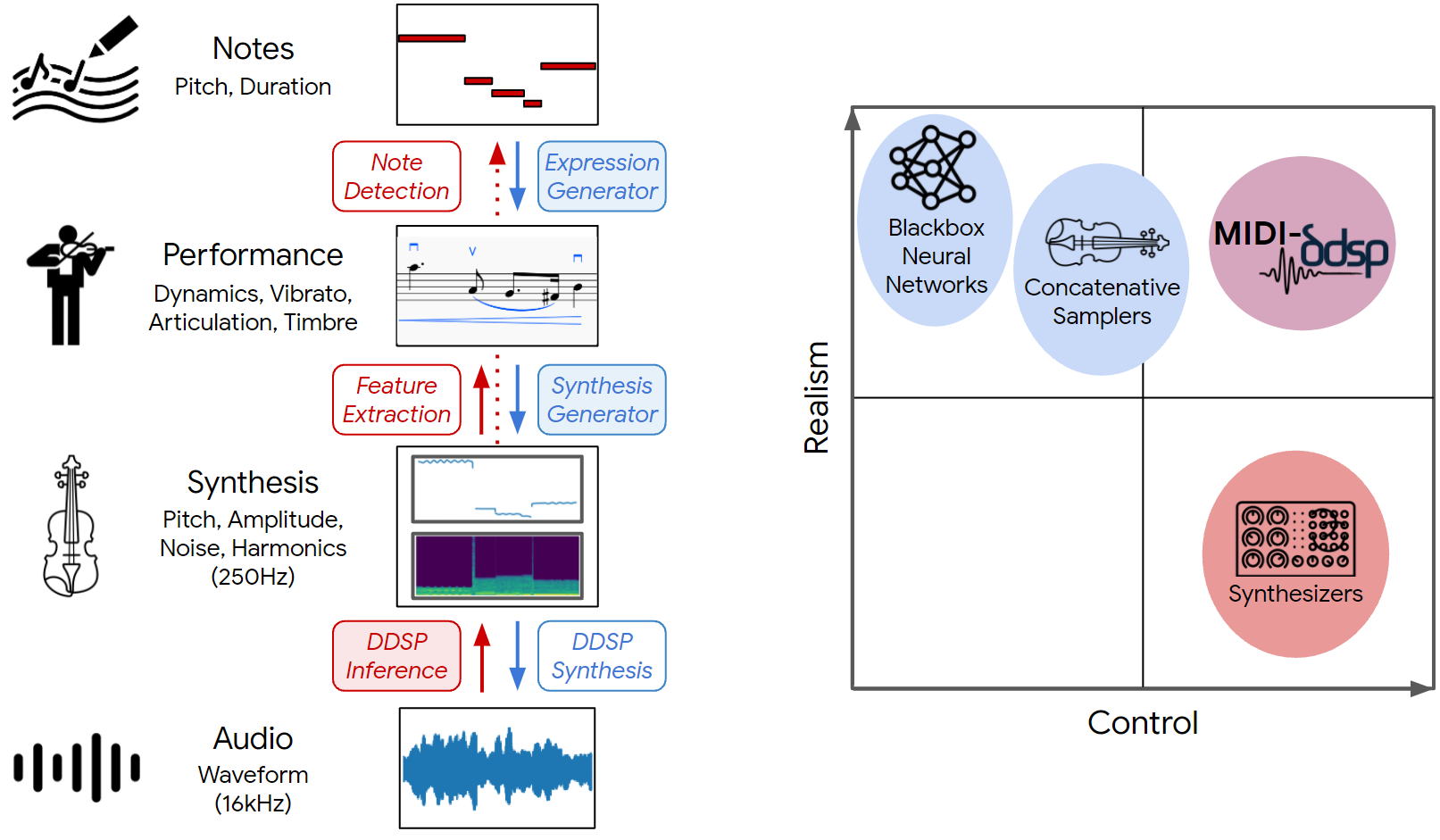
Hierarchical Music Generation with Detailed Control
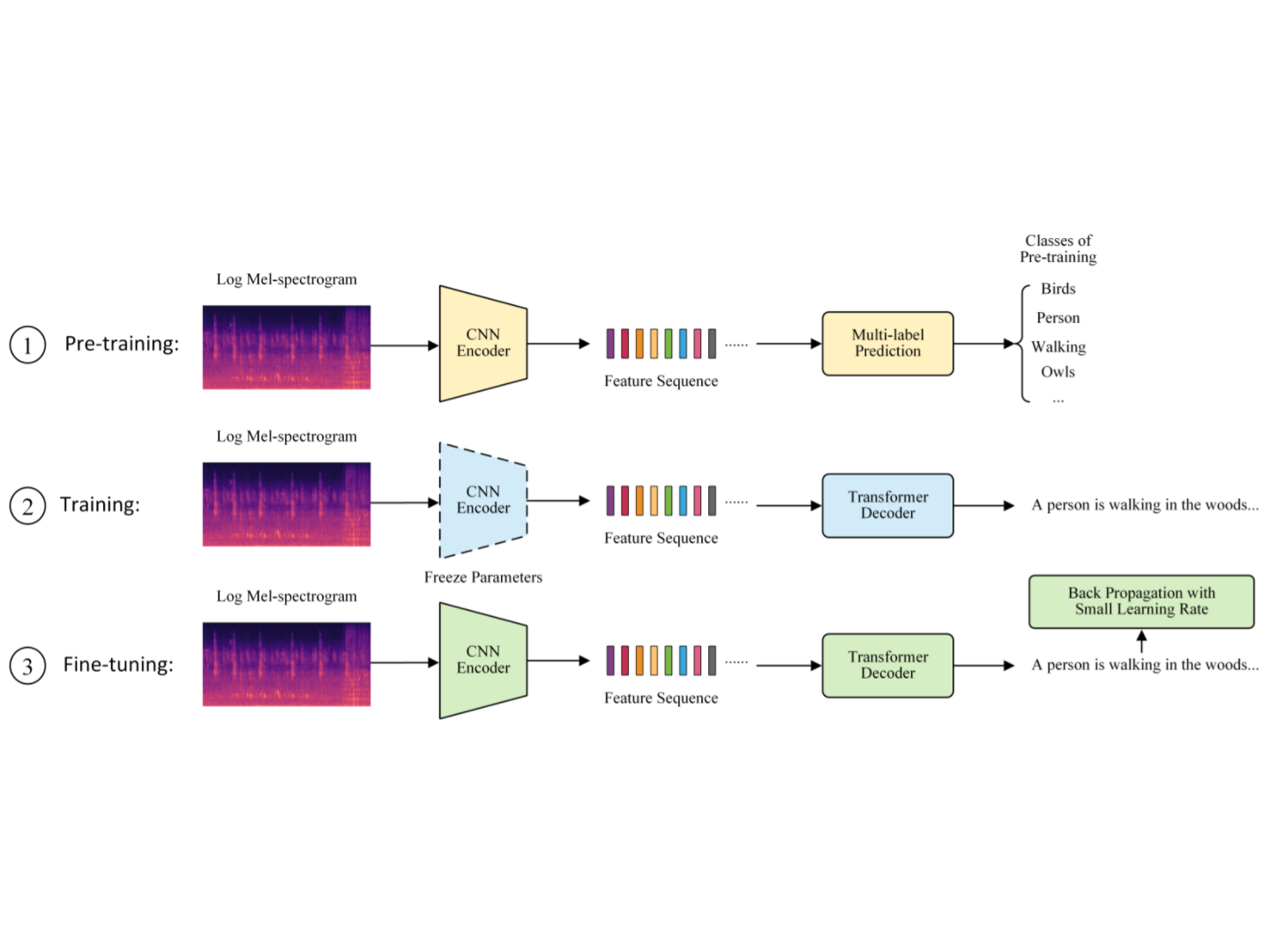
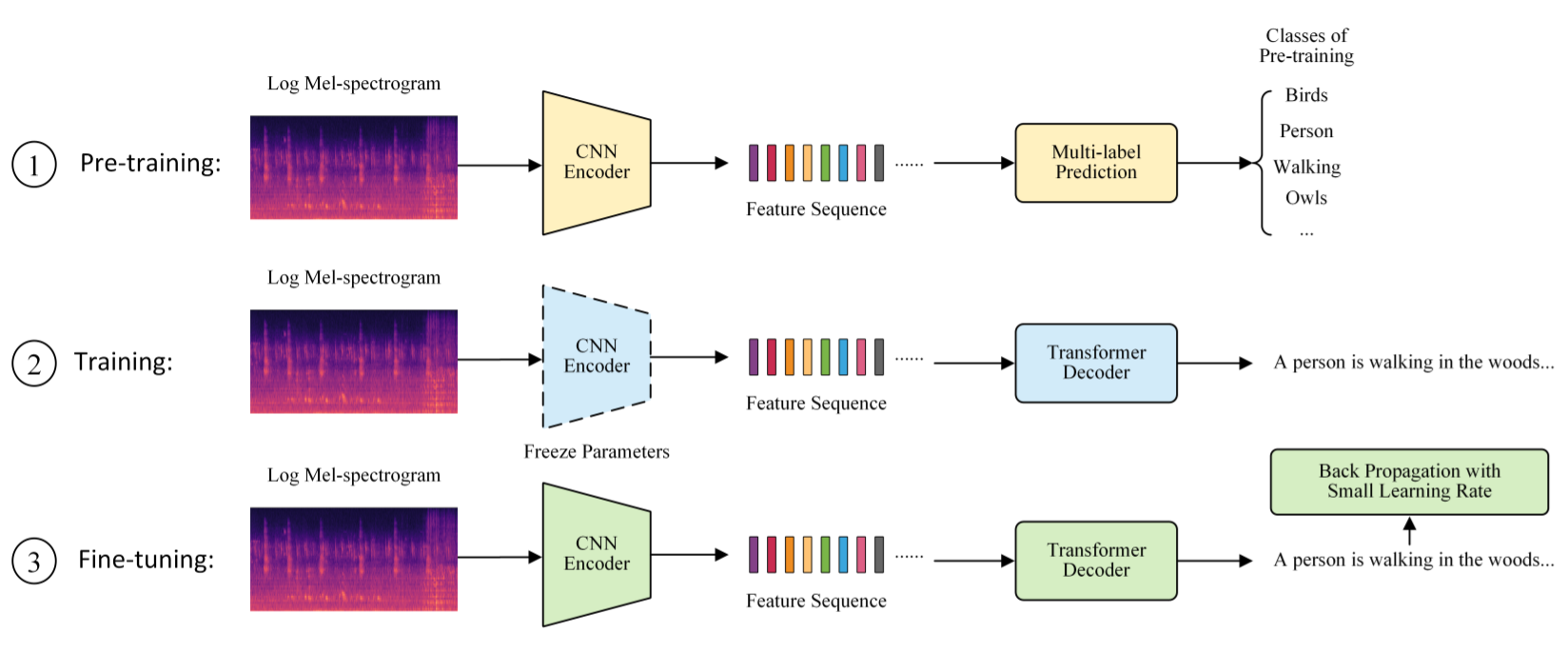
Automatic Audio Captioning with Transformer
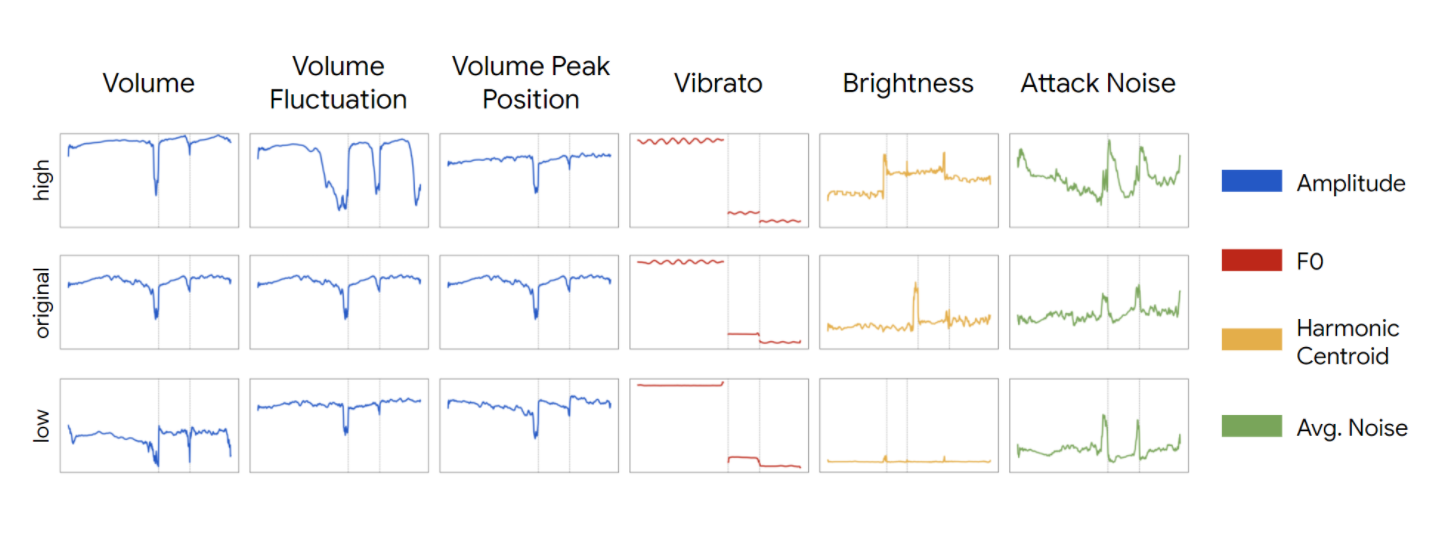
Expressive Peking Opera Synthesis

Chinese Guqin Dataset


Mila, University of Montreal
PhD Candidate in Computer Science - -
Conducting research on real-time, interactive music accompaniment models using reinforcement learning (RL) and multi-agent RL (MARL).
Adobe Research, Co-Creation for Audio, Video, & Animation
Student Researcher - -
Researched open-vocabulary audio event localization techniques conditioned on text prompts.
Google DeepMind, Magenta Team
Student Researcher - -
Developed a reinforcement learning-based system, ReaLchords, for real-time melody-to-chord accompaniment, and built GenJam, an interactive framework that enables delay-tolerant inference and anticipatory output visualization.
Mila, University of Montreal
CS Research Master - -
Worked on hierarchical music generation models with detailed control.

Tencent AI Lab
Research Intern - -
Developed expressive singing voice synthesis methods and explored dynamic vocal modeling.

Beijing University of Posts and Telecommunications
-
Research focused on audio captioning, symbolic music datasets, and computational musicology.
Hierarchical Music Generation with Detailed Control

Code | Blog | Colab Notebook | Huggingface Space | Command-line MIDI Synthesis
Automatic Audio Captioning with Transformer
Chinese Guqin Dataset

Collect and construct a symbolic music dataset of Chinese Guqin Dataset. Dataset is also used for proposing a statistical approach to distinguishing different music genre.
3rd Place at AI Song Contest 2022

Together with Yuxuan Wu and Yi Deng, we created a song about the growth of the AI model from its own perspective using music generation models. The song was ranked 3rd in the contest. To learn more about the song, please visit here.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
We propose MusicLDM, a text-to-music diffusion model that trains efficiently on limited dataset and avoid plagiarism. We leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. To learn more: sample page, code,paper.
CLAP: large-scale contrastive language-audio model
Together with Stability.ai, we created CLAP, a large-scale contrastive language-audio representation learning model. CLAP has been used in many projects and has been chosen widely be community for standard feature extraction model to calculate Frechet Audio Distance. To learn more: model github, data,paper.
ReaLchords and GenJam: Real-time Melody-to-chord Accompaniment via RL
We introduce MusicLDM, a text-to-music diffusion model designed to train efficiently on limited datasets and avoid musical plagiarism. By leveraging beat-synchronous audio mixup strategies, MusicLDM generates novel, stylistically faithful music. To learn more: ReaLchords webpage,ReaLchords paper, GenJam webpage.
FLAM: Frame-wise Language-Audio Modeling
FLAM aligns language and audio at the frame level, enables open-set sound event detection and unlocking fine-grained multimodal tasks such as text-conditioned audio generation, localization, and separation.