This paper presents a method that generates expressive singing voice of Peking opera. The synthesis of expressive opera singing usually requires pitch contours to be extracted as the training data, which relies on techniques and is not able to be manually labeled. With the Duration Informed Attention Network (DurIAN), this paper makes use of musical note instead of pitch contours for expressive opera singing synthesis. The proposed method enables human annotation being combined with automatic extracted features to be used as training data thus the proposed method gives extra flexibility in data collection for Peking opera singing synthesis. Comparing with the expressive singing voice of Peking opera synthesised by pitch contour based system, the proposed musical note based system produces comparable singing voice in Peking opera with expressiveness in various aspects.
In short: the model generates singing voice of Peking Opera from note and phoneme sequence where pitch, dynamics and timbre are jointly sampled.
How it works?
A phoneme encoder first encode contextual phoneme features.
Then alignment model is used to add note information as well as other conditions (singer, role type) and align all feature sequence with the output frame.
Auto-regressive decoder is used to generate spectrogram.
Griffin-Lim or neural vocoder such as WaveRNN is used to generate audio signal from spectrogram.
Audio Samples
Singing Synthesis
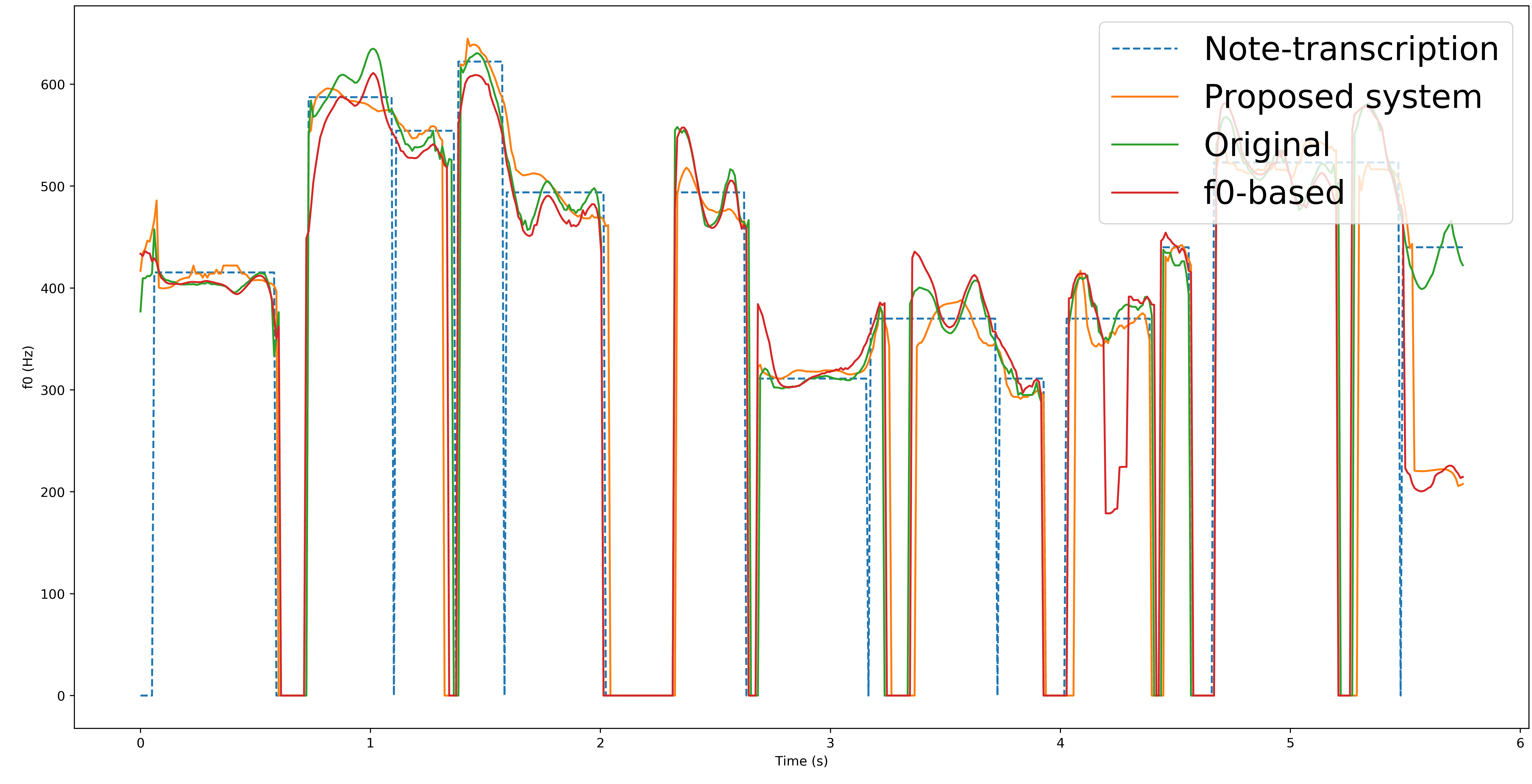
To verify the ability of the proposed method to successfully generate the pitch expressiveness out of musical note, the proposed method is compared with the original recording and a f0-based system where fundamental frequency (f0) is used as input instead of note.
*: Griffin-Lim is used here as vocoder which contributes the bad sound quality.
Original
f0-based System
Proposed Method
Original
f0-based System
Proposed Method
Original
f0-based System
Proposed Method
Original
f0-based System
Proposed Method
Original
f0-based System
Proposed Method
Original
f0-based System
Proposed Method
Singing Conversion
As our model are conditioned on singer identity (an embedding vector for each singer), singer conversion is possible, specifically, singing conversion across gender:
Original-Female
Conversion-Male
Original-Female
Conversion-Male
Original-Male
Conversion-Female
Original-Male
Conversion-Female
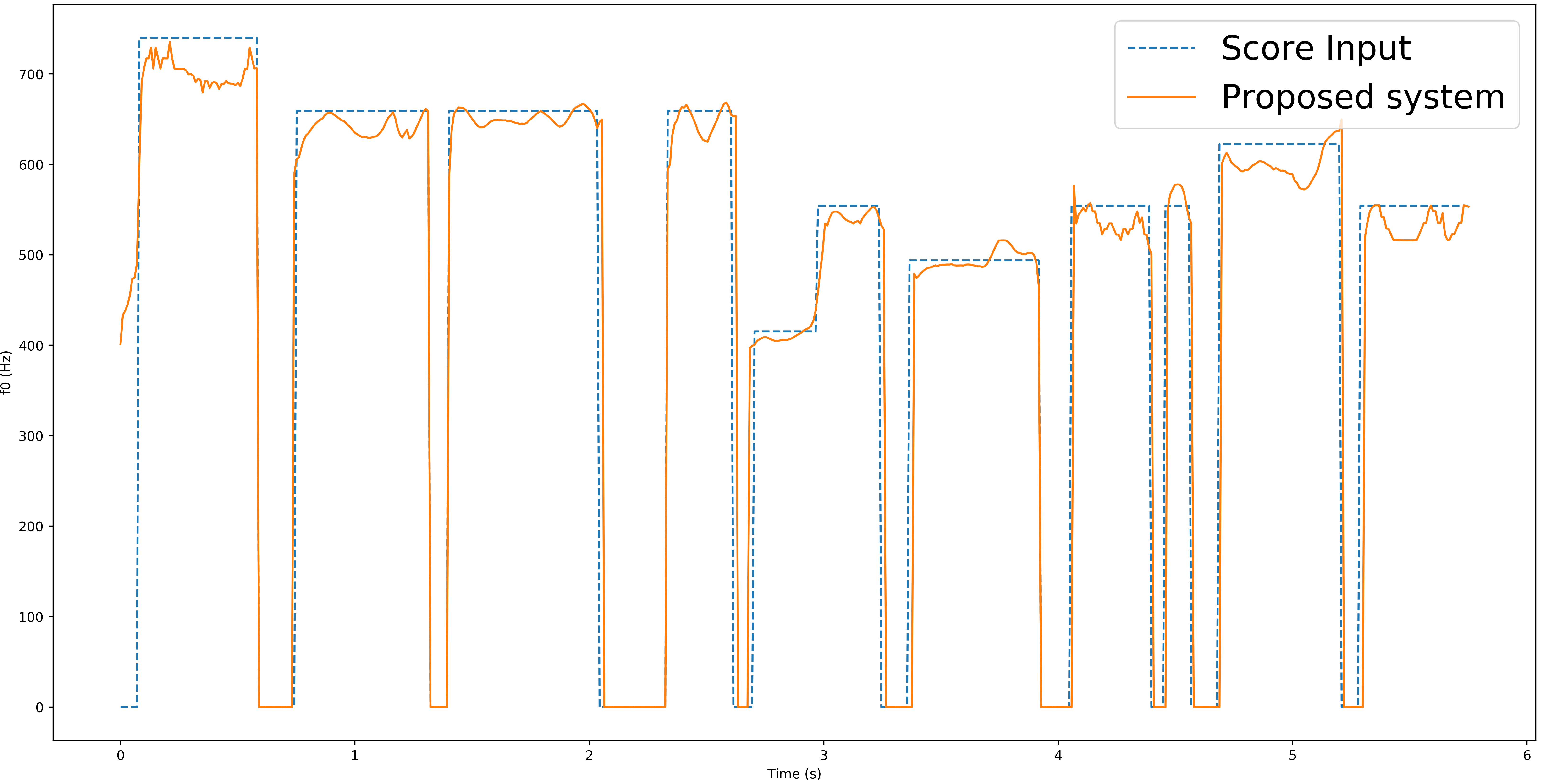
Score Input
In training, our note is obtained by note-transcription algorithm. To prove it can be generalised to score input, we used the published score of the recording to synthesis.
Note: the key and pitch contour of the score is different from the recording, which is why we do not use score-alignment in training.